مقایسه روش های یادگیری ماشین: کدام الگوریتم برای شما مناسب است؟

یادگیری ماشین (Machine Learning) شاخهای از هوش مصنوعی است که به سیستمها امکان میدهد بدون برنامهریزی صریح، از دادهها یاد بگیرند و عملکرد خود را بهبود بخشند. این فناوری در حوزههای مختلفی مانند: تشخیص گفتار، بینایی کامپیوتر، تحلیل دادهها و … کاربرد دارد. در این مقاله، به بررسی روش های یادگیری ماشین و کاربردهای آنها میپردازیم.
انواع روش های یادگیری ماشین
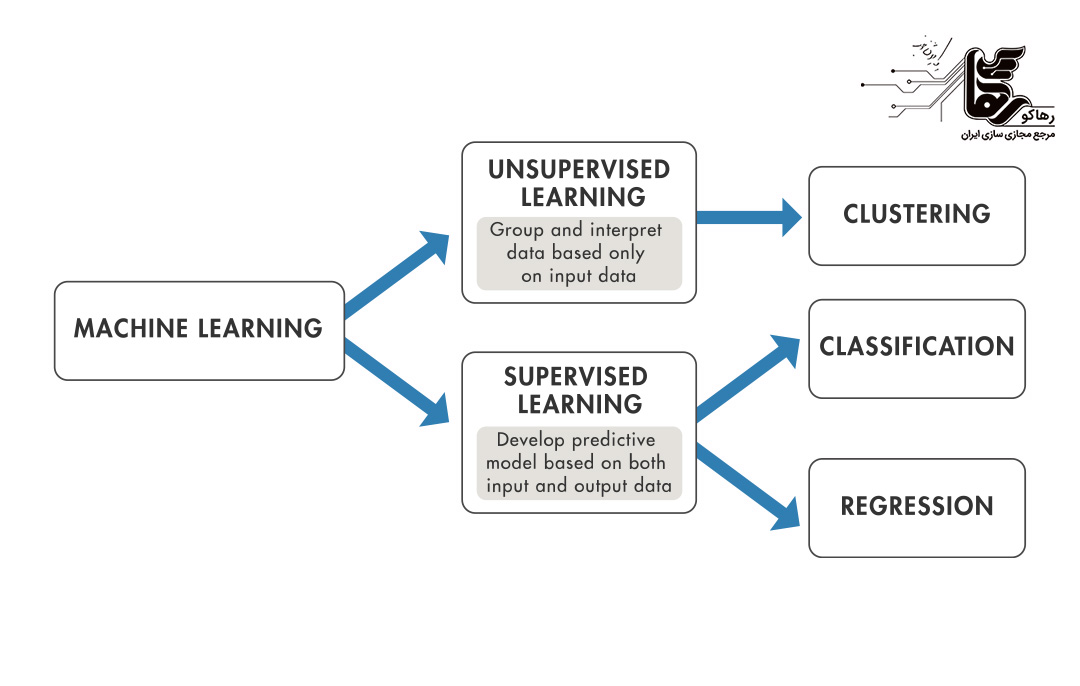
روشهای یادگیری ماشین به چهار دسته اصلی تقسیم میشوند. در ادامه، هر یک از این روشها را به تفصیل بررسی میکنیم.
یادگیری نظارت شده (Supervised Learning)
در یادگیری نظارتشده، مدل با استفاده از دادههای برچسبگذاریشده آموزش میبیند. این بدان معناست که هر ورودی با خروجی مورد انتظار مرتبط است. هدف این است که مدل بتواند با تحلیل دادههای آموزشی، الگوها را شناسایی کرده و برای دادههای جدید پیشبینیهای دقیقی انجام دهد.
یادگیری بدون نظارت (Unsupervised Learning)
در یادگیری بدون نظارت، مدل با دادههای بدون برچسب کار میکند. هدف این است که مدل بتواند ساختارها و الگوهای پنهان در دادهها را شناسایی کند.
یادگیری نیمه نظارت شده (SemiSupervised Learning)
این روش ترکیبی از یادگیری نظارت شده و بدون نظارت است. در اینجا، مدل با مجموعهای از دادههای برچسب گذاری شده و بدون برچسب آموزش میبیند. این روش زمانی مفید است که برچسب گذاری تمام دادهها هزینه بر یا زمان بر باشد.
یادگیری تقویتی (Reinforcement Learning)
یکی از روش های یادگیری ماشین یادگیری تقویتی است. یک عامل (Agent) در یک محیط (Environment) با انجام اعمال (Actions) و دریافت پاداش یا تنبیه (Rewards/Penalties) یاد میگیرد که چگونه به هدف خود برسد. این روش بر اساس آزمون و خطا است و عامل سعی میکند استراتژیای را بیاموزد که بیشترین پاداش را در طولانیمدت کسب کند.

چالشهای یادگیری ماشین
با وجود مزایای قابلتوجه، یادگیری ماشین با چالشهای متعددی نیز مواجه است. برخی از این چالشها عبارتاند از:
کیفیت و حجم دادهها
یادگیری ماشین به دادههای باکیفیت نیاز دارد. اگر دادهها ناکافی، نامتعادل یا دارای نویز باشند، مدلهای یادگیری ماشین عملکرد مطلوبی نخواهند داشت. پیشپردازش دادهها یکی از مهمترین مراحل در یادگیری ماشین است که شامل پاکسازی، یکسانسازی، و نرمالسازی دادهها میشود.
انتخاب ویژگیها
انتخاب ویژگیهای مناسب تأثیر زیادی در دقت مدل دارد. داشتن ویژگیهای نامرتبط یا زائد باعث کاهش کارایی مدل میشود. الگوریتمهایی مانند تحلیل مؤلفههای اصلی (PCA) و Lasso Regression میتوانند به کاهش ابعاد دادهها کمک کنند.
بیش برازش (Overfitting) و کمبرازش (Underfitting)
- بیش برازش: زمانی رخ میدهد که مدل بیش از حد به دادههای آموزشی وابسته شده و در مواجهه با دادههای جدید عملکرد خوبی ندارد.
- کمبرازش: زمانی اتفاق میافتد که مدل به اندازه کافی پیچیده نیست و نمیتواند الگوهای پنهان را به درستی یاد بگیرد.
- برای جلوگیری از بیشبرازش و کمبرازش، میتوان از تکنیکهایی مانند Dropout، Regularization (مانند L1 و L2)، و افزایش حجم دادهها (Data Augmentation) استفاده کرد.
تفسیرپذیری مدلها
برخی از الگوریتمهای یادگیری ماشین مانند شبکههای عصبی مصنوعی (ANNs) و مدلهای مبتنی بر یادگیری عمیق (Deep Learning)، مدلهایی غیرشفاف هستند و به سختی میتوان دلیل پیشبینیهای آنها را توضیح داد. در صنایعی مانند پزشکی و مالی، تفسیرپذیری مدلها نقش حیاتی دارد. برای این منظور، میتوان از تکنیکهایی مانند LIME (Local Interpretable ModelAgnostic Explanations) و SHAP (Shapley Additive Explanations) استفاده کرد.
زمان و منابع پردازشی
یادگیری برخی مدلها، مخصوصا مدلهای یادگیری عمیق، به منابع سختافزاری قوی مانند GPU و TPU نیاز دارند. در صورتی که قدرت پردازشی کافی در دسترس نباشد، ممکن است زمان آموزش مدلها بیش از حد طولانی شود. استفاده از رایانش ابری (Cloud Computing) و کتابخانههایی مانند TensorFlow و PyTorch میتواند این مشکل را کاهش دهد.
کاربردهای یادگیری ماشین در دنیای واقعی
الگوریتمهای یادگیری ماشین برای شناسایی چهره در تصاویر و فیلمها، بهبود کیفیت تصاویر، و تحلیل احساسات چهره مورد استفاده قرار میگیرند. شرکتهایی مانند Facebook و Google از این تکنولوژی برای بهینهسازی سیستمهای خود از انواع روش های یادگیری ماشین بهره میبرند. پردازش زبان طبیعی یکی از مهمترین شاخههای یادگیری ماشین است که برای تحلیل متن، ترجمه خودکار، و چتباتهای هوشمند استفاده میشود. نمونههایی از این تکنولوژی شامل Google Translate، ChatGPT، و Siri است.
سایتهایی مانند Netflix، Amazon و YouTube از یادگیری ماشین برای ارائه پیشنهادهای شخصیسازیشده به کاربران استفاده میکنند. این سیستمها با تحلیل رفتار کاربران، محصولات، فیلمها یا موسیقیهای مشابه را پیشنهاد میدهند. بانکها و شرکتهای مالی از الگوریتمها و روش های یادگیری ماشین برای شناسایی تراکنشهای مشکوک و جلوگیری از کلاهبرداری استفاده میکنند. این مدلها میتوانند الگوهای رفتاری غیرمعمول را شناسایی کرده و هشدارهای لازم را ارسال کنند.
یادگیری ماشین نقش مهمی در تشخیص سریع بیماریها، پردازش تصاویر پزشکی، و پیشبینی عوارض بیماران دارد. مدلهای یادگیری عمیق میتوانند تومورها را در تصاویر MRI و CT اسکن شناسایی کنند و به پزشکان در تصمیم گیری بهتر کمک کنند. خودروهای خودران مانند Tesla از یادگیری ماشین و بینایی کامپیوتر برای شناسایی محیط و اتخاذ تصمیمات رانندگی استفاده میکنند. این مدلها اطلاعاتی از حسگرها، دوربینها و رادارها را پردازش کرده و تصمیمات مناسب را در رانندگی اتخاذ میکنند.
نحوه انتخاب بهترین الگوریتم یادگیری ماشین
انتخاب الگوریتم مناسب بستگی به نوع مسئله، حجم دادهها و نیازهای پردازشی دارد. برای انتخاب بهتر، میتوان مراحل زیر را دنبال کرد:
- نوع مسئله را مشخص کنید (طبقهبندی، رگرسیون، خوشهبندی، یادگیری تقویتی).
- حجم دادههای موجود را بررسی کنید (برای دادههای زیاد، یادگیری عمیق مناسبتر است).
- دقت و زمان اجرا را مقایسه کنید (برخی الگوریتمها دقت بیشتری دارند اما کندتر هستند).
- نیاز به تفسیرپذیری را در نظر بگیرید (در مسائل حساس مانند پزشکی، مدلهای قابل تفسیر ارجحیت دارند).
- مدلهای مختلف را تست و مقایسه کنید (استفاده از معیارهایی مانند دقت (Accuracy)، فراخوانی (Recall)، و میانگین مربعات خطا (MSE) مفید است).
جمع بندی
یادگیری ماشین یکی از تحول آفرین ترین تکنولوژیهای عصر دیجیتال است که در بسیاری از صنایع مورد استفاده قرار میگیرد. این فناوری شامل روشهای مختلفی مانند یادگیری نظارت شده، بدون نظارت، نیمه نظارت شده و تقویتی است که هر یک کاربردهای خاص خود را دارند.
برای موفقیت در یادگیری ماشین، انتخاب الگوریتم مناسب، درک چالشهای دادهها و استفاده از تکنیکهای بهینه سازی بسیار مهم است. با گسترش کاربردهای هوش مصنوعی، انتظار میرود روش های یادگیری ماشین در آینده نقش پررنگتری در زندگی روزمره، کسب و کارها و تحقیقات علمی ایفا کند.