یادگیری ماشینی چیست؟
روشهای جدید در مدل یادگیری ماشینی ، با تمرکز دقیقتر بر روی دادههای بیشتر، منجر به پیشبینیهای قابل اعتمادتر میشود.
اگر راننده تاکسی شما از میانبر استفاده کند، ممکن است سریعتر به مقصد برسید. اما اگر یک مدل یادگیری ماشینی از میانبر استفاده کند، احتمال شکست خوردن آن افزایش مییابد.
چرا که در یادگیری ماشینی ، یک راه حل میانبر، زمانی رخ میدهد که مدل به جای یادگیری ماهیت واقعی دادهها، به ویژگی ساده یک مجموعه داده برای تصمیمگیری تکیه کند.
برای مثال، یک مدل ممکن است یاد بگیرد که تصاویر گاوها را با تمرکز بر روی چمن سبزی که در عکسها ظاهر میشود، شناسایی کند، نه اشکال و الگوهای پیچیدهتر در ماهیت خود گاوها.
یادگیری ماشینی چیست؟
با حذف ویژگیهای سادهای که تاکنون مدل ماشینی بر روی آنها تمرکز داشته است، محققان تلاش میکنند تا یادگیری ماشین را بر روی ویژگیهای پیچیدهتری که تا آن موقع در نظر گرفته نشده بود متمرکز کنند. سپس، با درخواست از مدل ماشین لرنینگ برای حل یک کار به دو روش، تمایل به راهحلهای میانبر را کاهش داده و عملکرد مدل را افزایش میدهند.
یکی از کاربردهای بالقوه این کار، افزایش اثربخشی مدلهای یادگیری ماشین است که برای شناسایی بیماری در تصاویر پزشکی استفاده میشوند. راه حلهای میانبر در این زمینه میتواند منجر به تشخیصهای نادرست شود و پیامدهای خطرناکی برای بیماران داشته باشد.
جاشوا رابینسون دانشجوی دکترای آزمایشگاه علوم کامپیوتر و هوش مصنوعی (CSAIL) و نویسنده اصلی مقاله میگوید: اگر بتوانیم نحوه عملکرد میانبرها را با جزئیات بیشتر درک کنیم، میتوانیم حتی فراتر برویم و به برخی از سوالات اساسی اما بسیار کاربردی که برای افراد بسیار مهم هستند پاسخ دهیم.

راه طولانی برای درک میانبرها
محققان مطالعه خود را بر یادگیری متضاد متمرکز کردند، که یک شیوه موثر در خودآموزی ماشین لرنینگ است. یک مدل یادگیری ماشینی خودآموز، بخشهای مفیدی از دادهها را میآموزد که به عنوان ورودی برای کارهای مختلف مانند طبقهبندی تصویر استفاده میشوند. اما اگر مدل از میانبرها استفاده کند و نتواند اطلاعات مهم را بگیرد نتیجه نهایی مطلوب نخواهد بود.
برای مثال، اگر یک مدل خودآموز یادگیری ماشینی، برای طبقهبندی تصاویر ذاتالریه با اشعه ایکس در تعدادی از بیمارستانها آموزش دیده باشد. یاد میگیرد که براساس برچسب بیمارستانی که اسکن از آنجا آمده است، پیشبینی کند. و در این حالت زمانی که دادههای یک بیمارستان جدید به آن داده میشود، عملکرد خوبی نخواهد داشت.
برای مدلهای یادگیری متضاد، یک الگوریتم رمزگذار برای تمایز بین جفت ورودیهای مشابه و جفت ورودیهای غیرمشابه آموزش داده شده است. این فرآیند داده های غنی و پیچیده مانند تصاویر را به گونهای رمزگذاری میکند که مدل یادگیری متضاد بتواند آن را تفسیر کند.
محققان، رمزگذارهای یادگیری متضاد را با مجموعهای از تصاویر آزمایش کردند و دریافتند که در طول این روش آموزشی، آنها طعمه راهحلهای میانبر نیز میشوند. رمزگذارها معمولا روی سادهترین ویژگیهای یک تصویر تمرکز میکنند تا تصمیم بگیرند که کدام جفت ورودی مشابه و کدام یک متفاوت هستند. جگلکا میگوید در حالت ایدهآل، رمزگذار باید هنگام تصمیمگیری بر روی تمام ویژگیهای مفید دادهها تمرکز کند. بنابراین، تیم محققان، تشخیص تفاوت بین جفتهای مشابه و غیرمشابه را سختتر کردند.
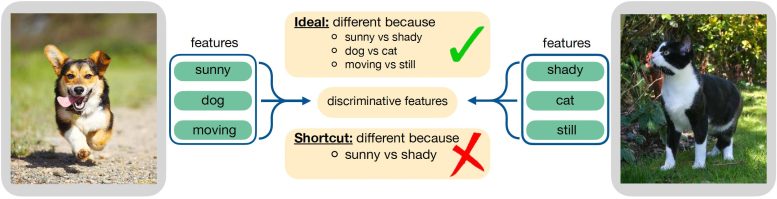
تفاوت جفت های مشابه و غیرمشابه
او میگوید: «اگر کار تمایز بین موارد مشابه و غیرمشابه را سختتر و سختتر کنید، سیستم شما مجبور میشود اطلاعات معنیدار بیشتری در دادهها جست و جو کرده و بیاموزد، زیرا بدون یادگیری نمیتواند مساله را حل کند.
اما افزایش این دشواری منجر به یک مبادله شد. رمزگذار در تمرکز بر برخی از ویژگیهای داده بهتر شد اما در تمرکز بر برخی دیگر بدتر شد. رابینسون میگوید که تقریباً به نظر میرسید ویژگیهای سادهتر را فراموش کرده است.
برای جلوگیری از این مبادله، محققان از رمزگذار خواستند تا به همان روشی که در ابتدا با استفاده از ویژگیهای سادهتر و همچنین پس از حذف اطلاعاتی که قبلا مدل ماشین لرنینگ آموخته بود، بین جفتها تمایز قائل شود. حل مساله به هر دو صورت به طور همزمان باعث بهبود رمزگذار در همه ویژگیها شد. روش آنها که اصلاح ویژگی ضمنی نامیده میشود، نمونهها را به صورت تطبیقی اصلاح میکند تا ویژگیهای سادهتری را که رمزگذار برای تمایز بین جفتها استفاده میکند حذف کند.
نتیجه گیری
یادگیری ماشینی به ورودی از جانب انسان متکی نیست، که نکته بسیار مهمیست. زیرا مجموعه دادههای دنیای واقعی می توانند صدها ویژگی مختلف داشته باشند که به روشهای پیچیدهای ترکیب میشوند. این موضوع به برخی از بزرگترین سوالات در مورد سیستمهای یادگیری عمیق مرتبط است، مانند «چرا آنها شکست میخورند؟» و «آیا میتوانیم از قبل موقعیتهایی را پیش بینی کنیم که مدل ماشین لرنینگ در آن شکست میخورد؟». هنوز راه زیادی در پیش است!